consumption carcass
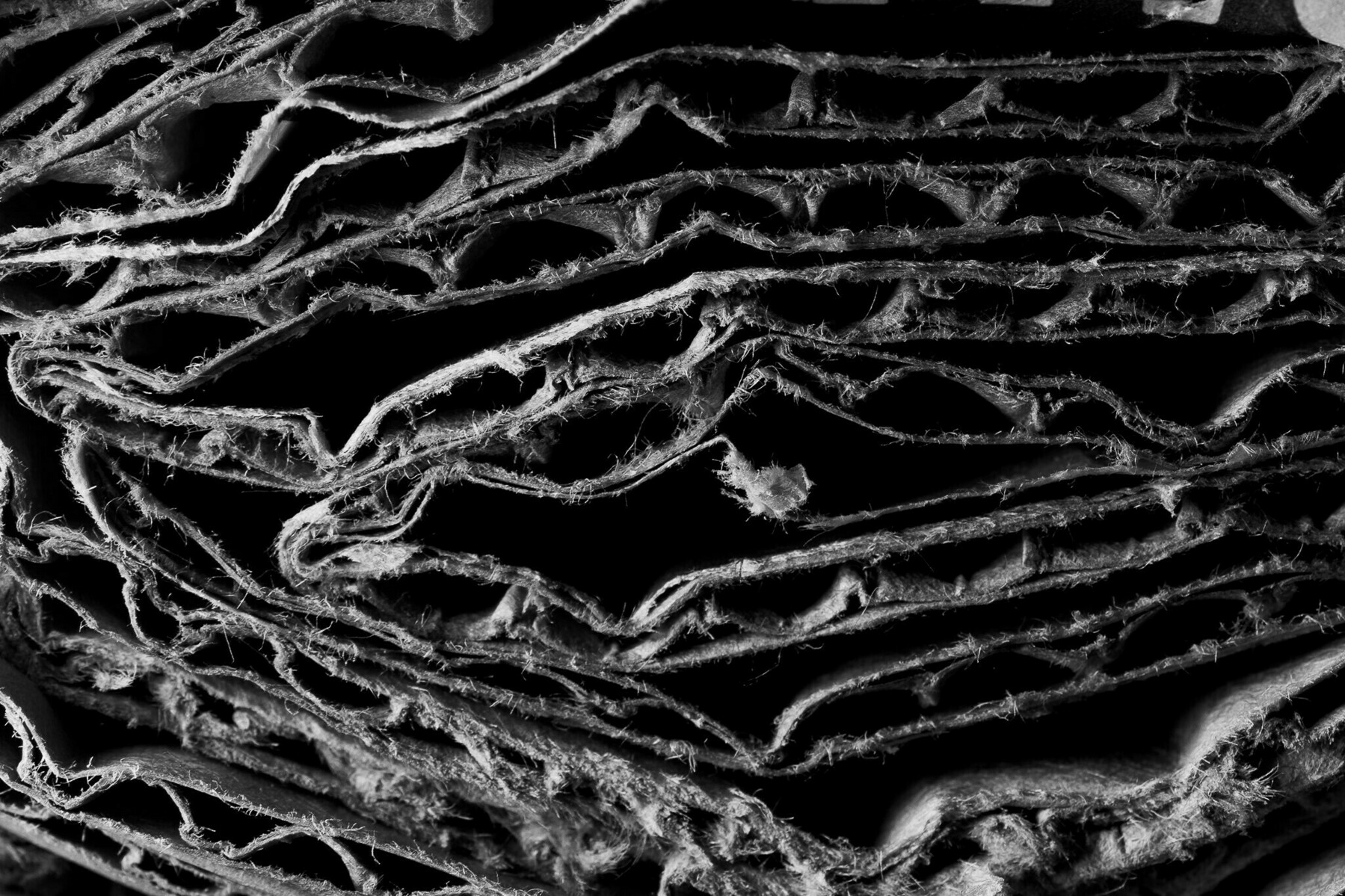
consumption carcass
inside an electric violin (Laowa probe lens, focus-stacked)

I’ve recently learned of several excellent and relatively new technical and research blogs that appear to be published with static site generators. On the surface, it is encouraging that talented communicators have not completely abandoned blogging as a (lowercase) medium in favor of the Mediums and Substacks of the contemporary internet.
The troubling detail I’ve noticed, however, is that very few of these sites are configured to also expose an RSS feed — so the primary way to find out about new posts is to follow the author on a social media site and watch for links.
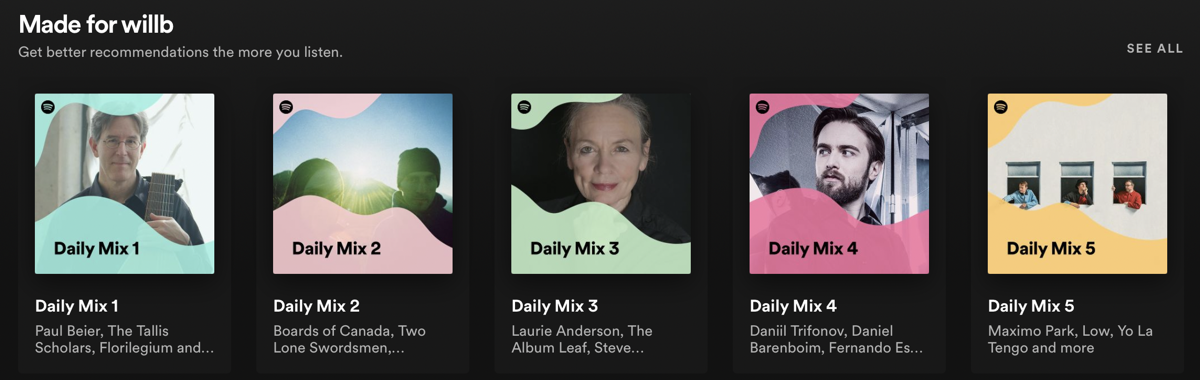
I don’t always listen to my Spotify “daily mixes,” which are algorithmically-generated playlists covering the constellation around a genre, but on most days at least one of mine is devoted to early music.
I was listening to one such playlist the other night and noticed Claudin de Sermisy’s “Tant que vivray”. I’ve noticed in the past that this piece comes up often in algorithmic playlists — it’s almost always in my early music playlists — and suspect that its popularity on streaming services is due to its place in the Norton Recorded Anthology of Western Music.
Since nearly every American who has taken undergraduate music history in the last forty years has studied this piece, it’s not surprising that automated recommendations favor “Tant que vivray,” especially since these students first encountered it at a crucial point in the term: the later French Renaissance is dramatically more accessible to contemporary ears than most of the western art music that preceded it. However, it’s possible to improve on even a great original: Miguel de Fuenllana’s intabulation of “Tant que vivray” for vihuela is a beautiful consequence of Sermisy’s chansons reaching Spain.
quiet on State Street

Feynman’s quip “if you’re the smartest person in the room, you’re in the wrong room” is well-known, but my friend Erik Erlandson recently glossed it and made me chuckle:
Every finite set has a maximum, so someone is always in the wrong room 😬
As an enthusiastic observer of human social dynamics, I don’t have a problem maintaining a high degree of confidence that, in general and for any given room, at least someone shouldn’t be there. But as someone who spent more than a few years of his youth thinking about how best to model things with lattices and semilattices, my immediate reaction was that Erik’s claim is only true if the relevant ordering is total, and it’s not obvious that every possible pair of humans is directly comparable by the “smarter-than” relation.
More fundamentally, though, it seems like looking at the problem of when to leave a room from the perspective of a “smarter-than” relation is the wrong model: people in a room can have complementary gifts and aptitudes. You may know more about historical performance practice for preclassical opera buffa than your friend Alice does, and Alice may know more about manual joinery than you do. If your goal is to build an authentic theatre dedicated to Pergolesi, you’d better both stay in the room.
For real humans in real situations, a better question is whether or not a given room offers one sufficient opportunity to exploit one’s strengths, improve upon one’s weaknesses, and benefit from at least someone else in the room while making the whole room better than the sum of the individuals therein. Engineers in particular are tempted to self-evaluate based on some perceived total ordering of intrinsic worth, but a good leader will redirect this impulse – instead of “How close am I to being the smartest person in this room?” you should ask two related questions: “Am I having a positive impact on this room?” and “is being in this room having a positive impact on me?”
No matter who’s “smartest,” there is almost always something for you to learn from the other people in the room. Make it your goal to find it before you decide you need to leave.
My old pal Tim St. Clair recently lamented about the state of configuration languages on Twitter:
The world desperately needs a configuration language that isn’t YAML or JSON. Something that is “expressive enough” yet “simple enough”. That balance is super hard.
Since thinking about the semantics of configuration systems and languages is a longstanding hobby of mine, I chimed in:
Part of the problem is endemic confusion over what constitutes a “language” — at best, YAML and JSON are human-readable serialization formats for abstract syntax trees.
So many extant DSL designs clearly start and end with AST serialization, never getting to semantics or UX.
Which led to a great question from Justin Taylor-Berrick:
Is the problem, then, that YAML and JSON are poor ASTs? The configuration languages all build up from data and add their features, rather than us agreeing on an AST between human friendly languages and data? Maybe we are missing an abstraction layer.
I can’t answer Justin properly in a Tweet, so I’m doing it here.
I really like the way Justin notes that starting with a serialization format and adding some ad hoc operations isn’t ideal: this results in “languages” that are adequate at representing the data they’re supposed to manipulate but probably aren’t as good at expressing the operations we’d like to perform on that data as they could be, to say nothing of establishing any guarantees about the transformations we’re performing or providing a predictable and consistent developer experience.1
In the case of Kubernetes in particular, “configuration languages” generally don’t do much beyond specifying API objects (sometimes parameterized at configuration time) that should or should not exist. This is actually not as bad as it sounds, given how Kubernetes works! (In general, you could do worse than using an established API as a starting point for a DSL.) But it would be better to provide higher-level query, coordination, and templating operations over these, and that’s where the complexity comes in.
A serious problem with the approach of starting with API objects and adding templating is that templating languages are extraordinarily difficult to get right. Existing templating facilities are often full of usability pitfalls because they have grown organically to satisfy certain applications. This sort of language evolution leads to many corner cases and inconsistencies. (Consider, for example, whether anyone could reliably document the semantics of PHP, or whether you’d be more inclined to trust a page-long Scheme program or a page-long Perl script.)
Syntax, whether concrete or abstract, isn’t the most interesting or difficult part of DSL (or language) design, but it is the part that invites the most bikeshedding. Most designers of YAML- or JSON-based “DSLs” seem to have put some thought into what the nouns should be called and into what files should look like in their editors but not into what things should mean or do. This is great if one’s goal is to design a language that one will enjoy seeing in an editor window, to the extent that one can enjoy looking at serialized nested lists and dictionaries in an editor window, but it is less great if one’s goal is to design a language that will not confuse its users.
Amateur language designers often think about incidental features of how they like languages to look and enjoy combining these incidental features in a novel way. Starting with an AST (and using a textual serialization format) means that they don’t have to develop a lexer or parser; failing to design the language beyond the AST means that the language is essentially a way to construct API objects (whether the API is for the system being configured or for the configuration system itself). This provides little value above simply publishing the API, but can potentially introduce usability headaches if, e.g., not every feature of the API is exposed, or if the semantics of iteration or variable-expansion facilities are unclear.
Flexible configuration is often really multi-stage programming, and we want a way to check, document, and test our configurations in the same way we check, document, and test our programs. It would be better to approach configuration by starting with a lightweight general-purpose programming language2, removing unnecessary features almost to the point of austerity, and enriching this core language with built-in functions and literals for API objects from the system to be configured.
For (an intentionally-controversial) example: I hate XML, but no matter how much one hates XML, one has to acknowledge that the XPath, XQuery, and XSLT tooling is better for document query and manipulation than an ad hoc combination of YAML or JSON and some templating engine designed for the view layer of a web application. ↩︎
Almost certainly not a Turing-complete one. ↩︎
As part of my Sisyphean quest to find a bicycle computer that doesn’t make me want to start tracking my rides with an abacus or programmable loom, I recently bought a new Garmin device to replace a deceased old one. The new device is not yet enraging me; it has everything I liked about my old one, plus more, and it also works.
Part of the “more” is three new mountain bike metrics. The most obvious is a screen that pops up and beeps at you whenever you momentarily leave the ground, saying “Great Jump!” and telling you how long you were in the air, how far you traveled, and how fast you were going at takeoff. Given my level of mountain bike proficiency, I read “Great Jump!” as sarcastic every single time.
The other new metrics are called “Grit” and “Flow.” I’d not read the manual before my first ride but I remembered reading that “Grit” was a measure of the difficulty of the route and “Flow” was a measure of how well you maintained speed while descending.
I hit a few loops of smooth singletrack at the ski club and tried to increase my “Flow” score with each lap. No matter how much I focused on improving my “Flow” score — staying loose, breathing slowly, pretending that every instant of pressure on my brakes came from a finite budget — I couldn’t get my “Flow” above five or so for a given lap. I didn’t know what five flow meant or if it was any good, but I was confident I could do better.
When I got home, I read Garmin’s description of “Flow,” which told me two things:
Optimizing for the opposite of the right metric seems worse than the more common problem of optimizing for the wrong metric altogether; it’s probably worth looking out for in general.
Carmen (Bizet, 1875): Man disregards advice from woman, with grave consequences.
Orfeo ed Euridice (Gluck, 1762): Man disregards advice from deity, with grave consequences.
Der fliegende Holländer (Wagner, 1843): Woman disregards advice from ghost pirate, with grave consequences.
Così fan tutte (Mozart, 1790): The composer does not like his wife.
Fidelio (Beethoven, 1805–14): The composer likes the idea of having a wife, but would settle for a free and just society.
Tristan und Isolde (Wagner, 1865): The composer likes other people’s wives.
La Traviata (Verdi, 1853): All you need is love.
Pagliacci (Leoncavallo, 1892): The tears of a clown, when everyone’s around.
Die Zauberflöte (Mozart, 1791): You say you want a revolution, and your bird can sing.
Rienzi (Wagner, 1840): The composer would like to make some money in Paris.
Tannhäuser (Wagner, 1845): The composer demonstrates that the Twisted Sister/Tipper Gore feud would have had a much larger body count had it occurred in medieval Germany.
Die Meistersinger von Nürnberg (Wagner, 1868): The composer thinks you should know that he read your review and it still stings a bit.
Parsifal (Wagner, 1882): The composer spent a lot of late nights thinking aloud in his dorm room the semester he took Intro to World Religions.
Falstaff (Verdi, 1893): It might actually be possible to improve on Shakespeare.
Roméo et Juliette (Gounod, 1867): But not like this.
Das Liebesverbot (Wagner, 1836): And absolutely not like this.
La nozze di Figaro (Mozart, 1786): Rich people are terrible.
Madama Butterfly (Puccini, 1904): Americans are terrible.
La Bohème (Puccini, 1896): Infectious diseases are terrible.
Das Rheingold (Wagner, 1869): Teutonic deities are terrible.
Guillaume Tell (Rossini, 1829): Habsburgs are terrible.
Die Fledermaus (J. Strauss, 1874): Operetta is terrible.
For nearly all of my adult life, a large part of my job has involved communicating technical concepts. I like to imagine that I’ve developed a consistent voice, style, and visual language, and I’m also inclined to imagine that it has taken me a long time to get here. I recently needed to look over an old deck and was surprised to note that many elements of my current (and presumably at least somewhat refined) style were present in a talk I gave over a decade ago as a graduate student.
Here’s the old talk; for comparison, here’s a talk I gave this January. While I’m still improving at giving talks and designing visual explanations, I guess things haven’t changed as radically as I might have assumed.
I was reminded today that the delights of good cookbooks subsist not merely in explaining how to prepare particular dishes of interest but in introducing wonderful things that one didn’t even know were of interest.
This is true of the best technical writing structured around a cookbook metaphor, as well.